
初めに
Twitterを使っていて,「ツイートを分析してみたいな」みたいなことを思ったことありませんか?
特に、いいねランキングなどを作成できると,「どういうツイートが人気があるのか」、「どういうツイートが好まれやすいのか」を分析出来たり,libtwiのようないいねいランキングを作成することができます‼
しかし、このデータ収集をいちいち手作業でやっていると、凄い手間と時間がかかり、非常に効率が悪いです。
ということで、今回は、TwitterAPI(Tweepy)を使って、いいねランキングを一括で超簡単に取得する方法を解説していきたいと思います‼
TwitterAPIを登録しよう‼
TwitterAPIに登録します。(Twitter社が公式で出しているので、怪しいやつではないです。)
↓登録方法についてはこちらの記事を参考に‼

正直言ってTwitterAPIの登録は少しめんどくさいです。
でも、昔よりも遥かに審査が簡単になっており、昔だったら1週間ぐらいかけて登録するものだったんですが、最近は1時間もかからず登録できます。
そして、API keyとAPI secret key、さらに、Access keyと、Access secret keyの4つのkeyを取得してください。
TwitterAPIに登録できたら、次は、プログラムで使うPythonをインストールする方法について解説していきたいと思います‼
(プログラミングと聞いて一見難しそうに思うかもしれませんが、とても簡単なので、安心してください。)
Pythonをインストールする
プログラムでは、プログラミング言語として、Pythonを使用します。(一見難しそうと思うかもしれませんが、実は超絶簡単です‼)
まだ、インストールしてない方は一瞬でできるので、インストールしてください‼
↓Pythonのインストール方法はこちら‼‼

ライブラリのインストール
次に、ライブラリをインストールしていきます。(ブラウザでいう拡張機能みたいなもの。)
コマンドプロンプトを開いて、「pip install tweepy pandas pytz」と入力してEnterを押してください。
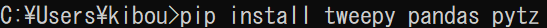
これで必要なライブラリのインストールは完了です。次は実際にプログラムを作っていきましょう‼
プログラムの作成
では、実際にプログラムを作っていきましょう‼
プログラムと聞くと難しそうだと思うかもしれませんが、コピペするだけなので簡単です。
まず、メモ帳を開いてください。

そして、メモ帳に下のコードをコピペします。
import tweepy
from datetime import datetime,timezone
import pytz
import pandas as pd
import datetime
# 認証に必要なキーとトークン
#先ほど取得したものを入力
API_KEY = ''
API_SECRET = ''
ACCESS_TOKEN = ''
ACCESS_TOKEN_SECRET = ''
# APIの認証
auth = tweepy.OAuthHandler(API_KEY, API_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET)
api = tweepy.API(auth)
dt_now = datetime.datetime.now()
#1時間前を取得したいので、hours=-1。もし1日前だったらdays=-1
dt_now2 = dt_now + datetime.timedelta(hours=-1)
now=dt_now.strftime('%Y-%m-%d_%H:%M:%S_JST')
before=dt_now2.strftime('%Y-%m-%d_%H:%M:%S_JST')
word="a"or"b"or"c"or"d"or"e"or"f"or"g"or"h"or"i"or"j"or"k"or"l"or"m"or"n"or"o"or"p"or"q"or"r"or"s"or"t"or"u"or"v"or"w"or"x"or"y"or"z"or"あ"or"い"or"う"or"え"or"お"or"か"or"き"or"く"or"け"or"こ"or"さ"or"し"or"す"or"せ"or"そ"or"た"or"ち"or"つ"or"て"or"と"or"な"or"に"or"ぬ"or"ね"or"の"or"は"or"ひ"or"ふ"or"へ"or"ほ"or"ま"or"み"or"む"or"め"or"も"or"や"or"ゆ"or"よ"or"ら"or"り"or"る"or"れ"or"ろ"or"わ"or"を"or"ん"or" "or"、"or"。"or"0"or"1"or"2"or"3"or"4"or"5"or"6"or"7"or"8"or"9"or"!"or"#"or"$"or"%"or"&"or"("or")"or"*"or"+"or","or"-"or"."or"/"or":"or";"or"<"or"="or">"or"?"or"@"or"["or"]"or"^"or"_"or"`"or"{"or"|"or"}"or"~"
#word='or'.join(map(lambda x: '"{}"'.format(x), list('abcdefghijklmnopqrstuvwxyzあいうえおかきくけこさしすせそたちつてとなにぬねのはひふへほまみむめもやゆよらりるれろわをん 、。0123456789!"#$%&()*+,-./:;<=>?@[]^_`{|}~')))
#print(len(api.search_tweets(q=word,lang='ja',since_id=before,until=now)))
#15分おきに300しか取得できないので注意
tweets = tweepy.Cursor(api.search_tweets,q=word,lang='ja',since_id=before,until=now).items(1000)
def change_time_JST(time):
utc = datetime.datetime(time.year, time.month,time.day, \
time.hour,time.minute,time.second, tzinfo=timezone.utc)
jst = utc.astimezone(pytz.timezone("Asia/Tokyo"))
str_time = jst.strftime("%Y-%m-%d_%H:%M:%S")
return str_time
tweet_data = []
for tweet in tweets:
#ツイート時刻とユーザのアカウント作成時刻を日本時刻にする
tweet_time = change_time_JST(tweet.created_at)
create_account_time = change_time_JST(tweet.user.created_at)
#tweet_dataの配列に取得したい情報を入れていく
tweet_data.append([
tweet.id,
tweet_time,
tweet.text,
tweet.favorite_count,
tweet.retweet_count,
tweet.user.screen_name,
tweet.user.name,
tweet.user.description,
tweet.user.friends_count,
tweet.user.followers_count,
create_account_time,
tweet.in_reply_to_status_id_str,
tweet.in_reply_to_user_id_str,
tweet.coordinates,
tweet.user.verified
])
#取り出したデータをpandasのDataFrameに変換
#CSVファイルに出力するときの列の名前を定義
columns=[
'ツイートID',
'ツイートされた時間(日本時間)',
'ツイートの内容',
'いいねの数',
'リツイートの数',
'ツイートした人のID',
'アカウント名',
'自己紹介文',
'フォロー数',
'フォロワー数',
'アカウント作成日時',
'ツイートが返信の場合、返信先のツイートID',
'ツイートが返信の場合、返信先のユーザーID',
'ツイートされた場所',
'認証アカウント(公式アカウント)かどうか'
]
#tweet_dataのリストをpandasのDataFrameに変換
df = pd.DataFrame(tweet_data,columns=columns)
df = df.sort_values('いいねの数', ascending=False)
#df = df.sort_values('いいねの数', ascending=False)
#CSVファイルに出力する
#CSVファイルの名前を決める
file_name='tweet3.csv'
#CSVファイルを出力する
df.to_csv(file_name,encoding='utf-8-sig',index=False)コードを貼り付けて保存する
メモ帳にコードを貼り付けます。
↓こんな感じ。

そして、「ctrl+s」をおして、下のような感じで保存します。(ファイル名の最後は、「.py」にしてください。)
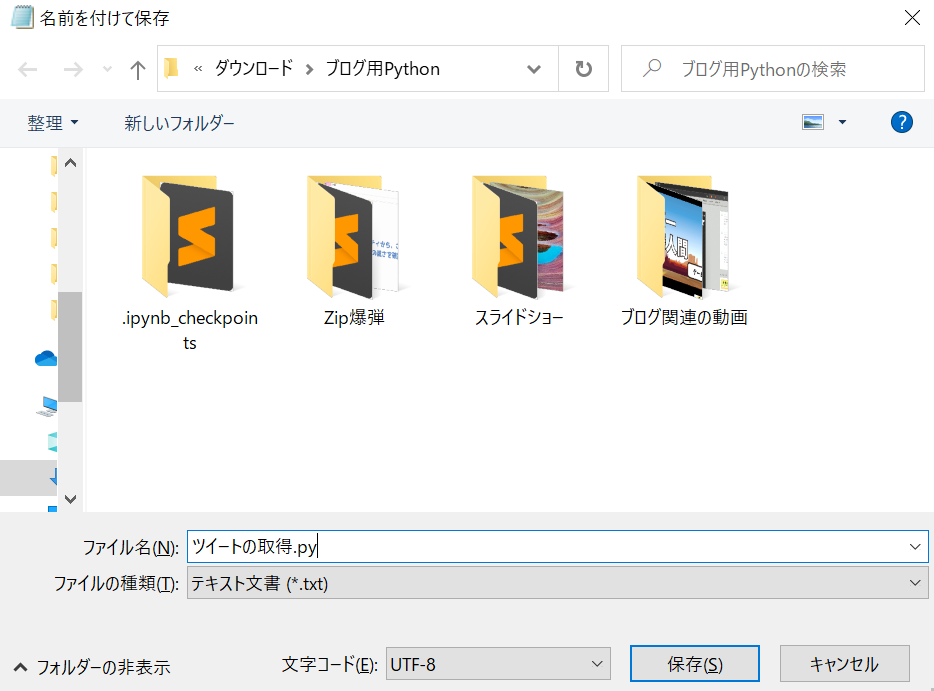
これで、プログラムの作成は完了です。
プログラムを実行
では、実際にプログラムを実行してフォロー解除していきましょう‼
先ほどのファイルを保存したディレクトリに行って、アドレスバーのところに「cmd」と入力してEnterを押してください。
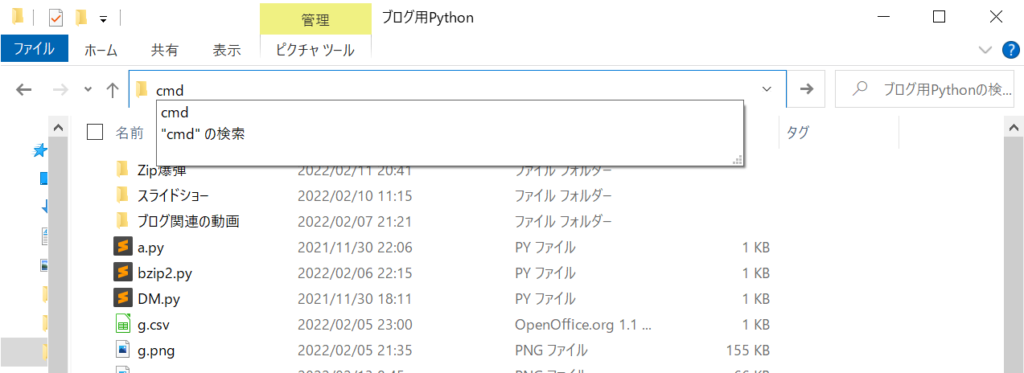
すると、コマンドプロンプトが起動すると思います。
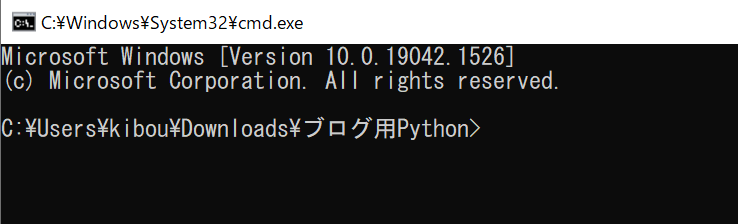
そして、「python ツイートの取得.py」と入力して、Enterを押してください。
これでプログラムの実行は完了です。
実際にツイートを取得できているか見ていきましょう‼
ツイートを取得できているか確認する
ツイートを取得できているか確認していきましょう‼
まず、先ほどのファイルを保存して実行したディレクトリを開いてください。
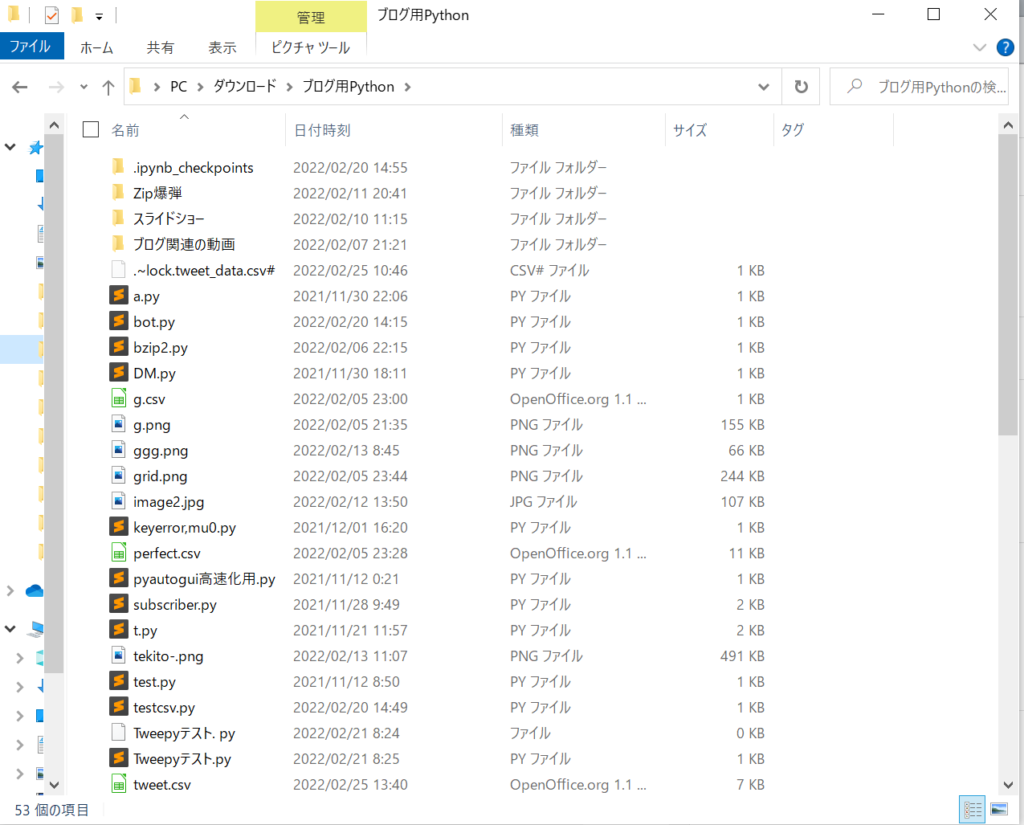
見てみると、下の赤丸で囲ったように、「tweet.csv」ができていると思います。
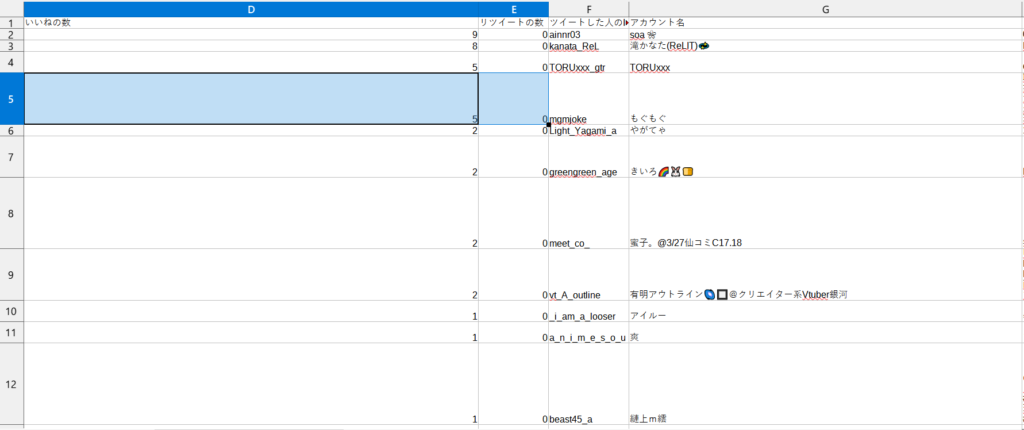
そして、中身を見てみると、ちゃんとツイートを取得できており、ちゃんといいねの数順に並んでいます。
これでTwitterAPIでいいねランキングを取得する方法の解説は終わりです‼
いいね○○以上と指定してツイートを取得する方法
ここからは本筋とは少しそれるんですが、「いいね○○以上と指定してツイートを取得」する方法について解説していきます‼
先ほどのプログラムのところを,
import tweepy
from datetime import datetime,timezone
import pytz
import pandas as pd
import datetime
# 認証に必要なキーとトークン
#先ほど取得したものを入力
API_KEY = ''
API_SECRET = ''
ACCESS_TOKEN = ''
ACCESS_TOKEN_SECRET = ''
# APIの認証
auth = tweepy.OAuthHandler(API_KEY, API_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET)
api = tweepy.API(auth)
dt_now = datetime.datetime.now()
#1時間前を取得したいので、hours=-1。もし1日前だったらdays=-1
dt_now2 = dt_now + datetime.timedelta(hours=-1)
now=dt_now.strftime('%Y-%m-%d_%H:%M:%S_JST')
before=dt_now2.strftime('%Y-%m-%d_%H:%M:%S_JST')
word="a"or"b"or"c"or"d"or"e"or"f"or"g"or"h"or"i"or"j"or"k"or"l"or"m"or"n"or"o"or"p"or"q"or"r"or"s"or"t"or"u"or"v"or"w"or"x"or"y"or"z"or"あ"or"い"or"う"or"え"or"お"or"か"or"き"or"く"or"け"or"こ"or"さ"or"し"or"す"or"せ"or"そ"or"た"or"ち"or"つ"or"て"or"と"or"な"or"に"or"ぬ"or"ね"or"の"or"は"or"ひ"or"ふ"or"へ"or"ほ"or"ま"or"み"or"む"or"め"or"も"or"や"or"ゆ"or"よ"or"ら"or"り"or"る"or"れ"or"ろ"or"わ"or"を"or"ん"or" "or"、"or"。"or"0"or"1"or"2"or"3"or"4"or"5"or"6"or"7"or"8"or"9"or"!"or"#"or"$"or"%"or"&"or"("or")"or"*"or"+"or","or"-"or"."or"/"or":"or";"or"<"or"="or">"or"?"or"@"or"["or"]"or"^"or"_"or"`"or"{"or"|"or"}"or"~"
#word='or'.join(map(lambda x: '"{}"'.format(x), list('abcdefghijklmnopqrstuvwxyzあいうえおかきくけこさしすせそたちつてとなにぬねのはひふへほまみむめもやゆよらりるれろわをん 、。0123456789!"#$%&()*+,-./:;<=>?@[]^_`{|}~')))
#print(len(api.search_tweets(q=word,lang='ja',since_id=before,until=now)))
#1000個取得。大きすぎるとエラーになるので注意‼
tweets = tweepy.Cursor(api.search_tweets,q=word,lang='ja',since_id=before,until=now).items(1000)
def change_time_JST(time):
utc = datetime.datetime(time.year, time.month,time.day, \
time.hour,time.minute,time.second, tzinfo=timezone.utc)
jst = utc.astimezone(pytz.timezone("Asia/Tokyo"))
str_time = jst.strftime("%Y-%m-%d_%H:%M:%S")
return str_time
tweet_data = []
for tweet in tweets:
if tweet.favorite_count>5:#いいねの数を5より大きい(6以上に指定)
#ツイート時刻とユーザのアカウント作成時刻を日本時刻にする
tweet_time = change_time_JST(tweet.created_at)
create_account_time = change_time_JST(tweet.user.created_at)
#tweet_dataの配列に取得したい情報を入れていく
tweet_data.append([
tweet.id,
tweet_time,
tweet.text,
tweet.favorite_count,
tweet.retweet_count,
tweet.user.screen_name,
tweet.user.name,
tweet.user.description,
tweet.user.friends_count,
tweet.user.followers_count,
create_account_time,
tweet.in_reply_to_status_id_str,
tweet.in_reply_to_user_id_str,
tweet.coordinates,
tweet.user.verified
])
else :
pass
#取り出したデータをpandasのDataFrameに変換
#CSVファイルに出力するときの列の名前を定義
columns=[
'ツイートID',
'ツイートされた時間(日本時間)',
'ツイートの内容',
'いいねの数',
'リツイートの数',
'ツイートした人のID',
'アカウント名',
'自己紹介文',
'フォロー数',
'フォロワー数',
'アカウント作成日時',
'ツイートが返信の場合、返信先のツイートID',
'ツイートが返信の場合、返信先のユーザーID',
'ツイートされた場所',
'認証アカウント(公式アカウント)かどうか'
]
#tweet_dataのリストをpandasのDataFrameに変換
df = pd.DataFrame(tweet_data,columns=columns)
df = df.sort_values('いいねの数', ascending=False)
#CSVファイルに出力する
#CSVファイルの名前を決める
file_name='tweet.csv'
#CSVファイルを出力する
df.to_csv(file_name,encoding='utf-8-sig',index=False)と書き換えることで、いいね○○以上のツイートを取得することができます。

↑こんな感じです。(データのサンプルが少なく、時間の条件が厳しかったので一つしかヒットしませんでした。)
「返信ツイートではないツイート」などのもっと詳しい条件を追加したい場合は、Pythonを勉強して、if関数などの条件分岐で適当に編集してください。(コメント欄で聞くのもOK)
終わりに
いかがでしたか。
これを使えば、ツイートを簡単に一瞬で一括取得することができて、分析とかする時に、データ収集が非常に楽になりますね。
もしわからないところや、エラーが出てきておかしいところ等ございましたら、コメント欄で気軽に聞いてください。
ほかにも面白い記事たくさんありますので、ほかの記事も一緒に見ていただければ嬉しいです。
それでは次の記事で‼


プロフィール
このブログの情報が少しでも役に立てれば嬉しいです。